


umm, before talking about the internal workflow of git.
let's see what git actually is!
So, git is a distributed version control system that tracks changes in any set of computer files, usually used for co-ordinating work among programmers who are collaboratively developing source code during software development.
In nutshell It's a devOps tool for source code management.
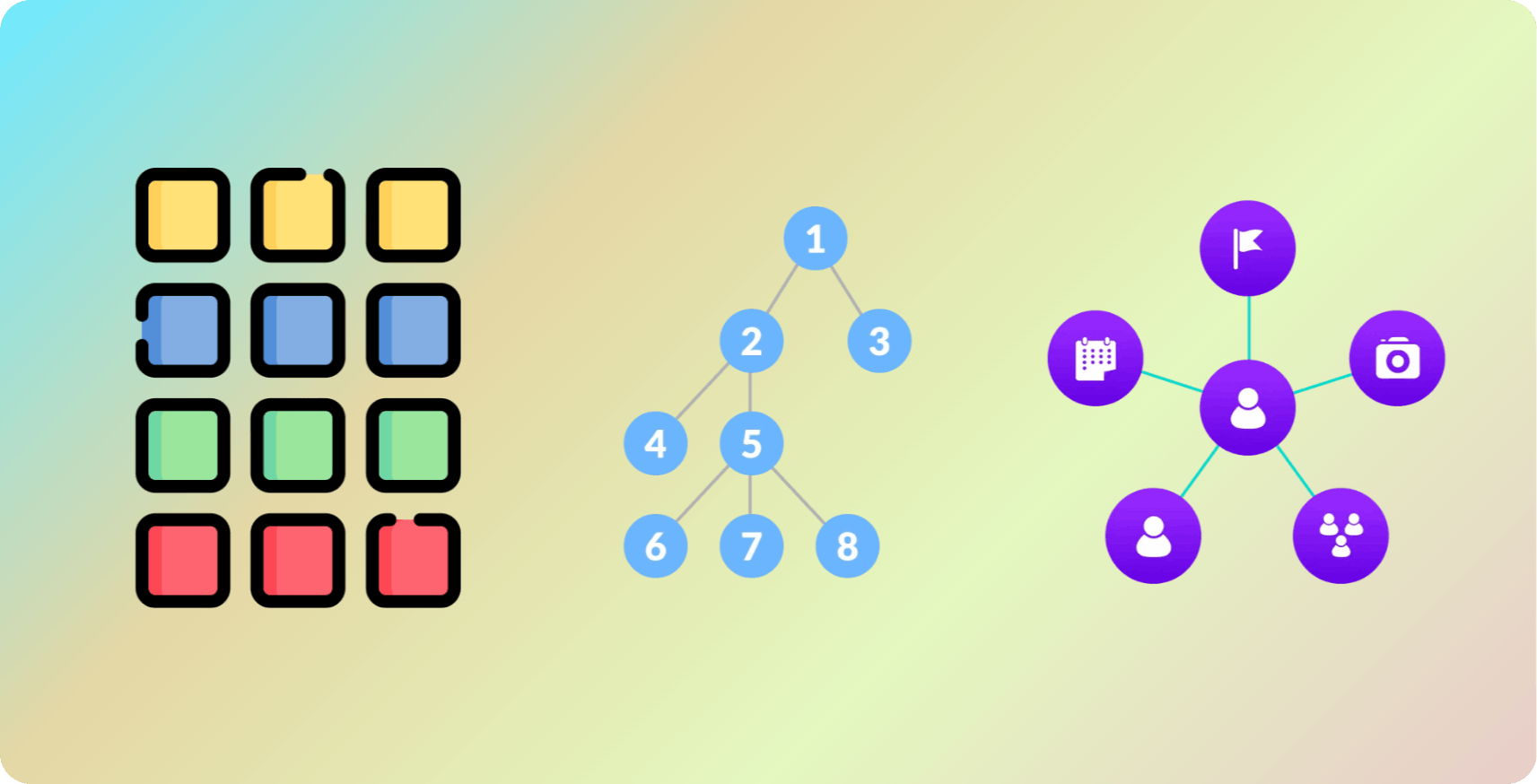
The main power-house of git
Hash-map
Tree Data Structure
Graph Data Structure
Git stores data in key-value pair, where key is the hash of the data and value is the data.
so, you must have seen something gibberish or absurd string shown in terminal said commit ID. when ever we commit our code.

What is that commit ID ?
That commit ID is the Hash-ID of the data(code), In our case that is our programme which we wrote to perform any specific task, it can be a giant server or small program to print "hello world"
Git uses cryptographic hash function(this crypto is not that of bitcoin’s, we are not making any crypto currencies here😅). which is SHA-1 for a given data, and the function returns the 40 digit hexadecimal number.
SHA-1 stands for Secure Hash Algorithm-1 is a cryptographic algorithm that takes an input and produces a 160-bit hash value. This hash value is known as a message digest and is usually rendered as a 40-digit hexadecimal number.
The interesting fact is no matter how many time you create the hash of the same data, hash will be the same
Let's see this in practice.

No matter how many times you try to create hash of "hello world", it will create the same Hash ID.
ok wait wait wait you must be thinking what is this gibberish command above.
No worries let's dig the command out.
echo "hello world" | git hash-object --stdin
| -> This character is called pipe, it is used to run two command simultaneously.
echo is used to print anything.
git hash-object --stdin is a command provided by the git itself to make hash of anything.
Here, we are running both command in one go.
So here, by this command we are making Hash ID of "hello world".
Now, as here our data is just "hello world", but in real scenario its a piece of code or it is many folder with many files of code.
So, git compresses the data in a blob and stores some metadata (data about the data), the data can be anything a single "hello world" string or a big code base.

BLOB stands for a “Binary Large Object,” a data type that stores binary data. Binary Large Objects (BLOBs) can be complex files like images or videos, unlike other data strings that only store letters and numbers.
Here, Git blob (binary large object) is the object type used to store the contents of each file in a repository. The file's SHA-1 hash is computed and stored in the blob object. These endpoints allow you to read and write blob objects to your Git database on GitHub Enterprise Cloud.
I hope you got an idea a bit.
Next we will talk about .git folder which is being made when we run commandgit init